
Desenvolvido pela DataCurve, o DeepSWE oferece uma referência para avaliar modelos de codificação de IA, concentrando-se em desafios de programação do mundo real, em vez de casos de teste sintéticos. Segundo Matthew Berman, uma de suas principais características é a utilização de tarefas não contaminadas, cuidadosamente projetadas para garantir que os modelos não encontrem problemas que possam ter encontrado durante o treinamento. Essas tarefas são extraídas de 91 repositórios de código aberto que abrangem linguagens como TypeScript, Go e Rust, fornecendo uma avaliação diversificada e prática de como os padrões de codificação governam diferentes paradigmas de programação. O sistema também inclui um sistema de testes rigoroso que minimiza erros e garante métricas de desempenho consistentes.
Mergulhe na forma como o DeepSWE avalia modelos de codificação para tarefas práticas, enfatizando a precisão comportamental e a eficiência de recursos. Saiba como o GPT 5.5 equilibra velocidade, custo e precisão, superando modelos como o Opus 4.7 em tempo de atividade e custo. Entenda as dificuldades enfrentadas por modelos como Claude Haiku 4.5 ao usar prompts de várias partes e explore como o DeepSWE facilita comparações significativas de sistemas de codificação de IA.
A importância de tarefas livres de contaminação
Chaves TL;DR:
- DeepSWE é um novo modelo de referência de codificação de IA que se concentra nos desafios de codificação do mundo real, garantindo que as tarefas sejam não poluídas, originais e imparciais.
- Ele avalia modelos em 91 repositórios de código aberto diferentes em cinco linguagens de programação (TypeScript, Go, Python, JavaScript, Rust) que representam a complexidade do mundo real e vários casos de uso.
- DeepSWE enfatiza a resolução prática de problemas com instruções concisas e altos requisitos de token, estreitamente alinhados com os desafios do desenvolvedor do mundo real.
- Os mecanismos de validação garantem resultados robustos com taxas de erro extremamente baixas (0,3% de falsos positivos, 1,1% de falsos negativos), proporcionando uma visão precisa do desempenho do modelo.
- O GPT 5.5 lidera em termos de desempenho, precisão de equilíbrio, economia e velocidade, enquanto outros modelos como o Opus 4.7 e Claude Haiku 4.5 destacam áreas para melhoria.
DeepSWE apresenta tarefas totalmente originais e feitas à mão para garantir uma avaliação imparcial. Ao evitar depender de conjuntos de dados públicos, como commits ou problemas do GitHub, isso garante que os modelos de IA sejam testados em problemas que não encontraram durante o treinamento. Isso remove contaminação de dadospermitindo uma avaliação mais precisa das verdadeiras habilidades de resolução de problemas do modelo. A ênfase na originalidade garante condições de concorrência equitativas, tornando o DeepSWE uma ferramenta confiável para avaliar modelos de codificação de IA.
Vários repositórios para testes extensivos
Para refletir a complexidade da codificação do mundo real, o DeepSWE inclui 91 repositórios ativos de código aberto em cinco linguagens de programação:
- Texto datilografado
- ir
- Pitão
- JavaScript
- Ferrugem
Essa diversidade reflete uma ampla gama de cenários de codificação, desde o desenvolvimento web até a programação em nível de sistema. Ao incorporar diferentes arquiteturas e casos de uso, o DeepSWE avalia quão bem os modelos se adaptam a diferentes paradigmas e desafios de programação. Esta abordagem abrangente garante que os modelos sejam testados em tarefas que se assemelham muito aos desafios que os desenvolvedores enfrentam no seu trabalho diário.
Melhore suas habilidades de benchmarking de IA lendo mais de nosso conteúdo aprofundado.
Complexidade do mundo real: uma referência para habilidades práticas
As tarefas do DeepSWE são projetadas para simular interações reais do desenvolvedor com agentes de codificação. As instruções são concisas, exigindo modelos para identificar e implementar soluções com orientação mínima. Ao contrário de outros benchmarks, o DeepSWE requer muito mais código e tokens de saídaencorajando modelos para resolver problemas práticos complexos. Isso garante que o benchmark corresponda com precisão aos desafios que os desenvolvedores enfrentam, tornando-o um verdadeiro teste das capacidades práticas do modelo de IA.
Verificação confiável de insights precisos
A verificação é a base da credibilidade do DeepSWE. Seus mecanismos robustos recompensam a correção em implementações válidas, resultando em taxas de erro extremamente baixas.0,3% para falsos positivos e 1,1% para falsos negativos. Comparado a benchmarks como o SWEbench Pro, o DeepSWE oferece uma avaliação mais precisa e fornece insights práticos sobre o desempenho do modelo. Este nível de precisão garante que os desenvolvedores e pesquisadores possam ter confiança nos resultados ao comparar diferentes modelos de codificação de IA.
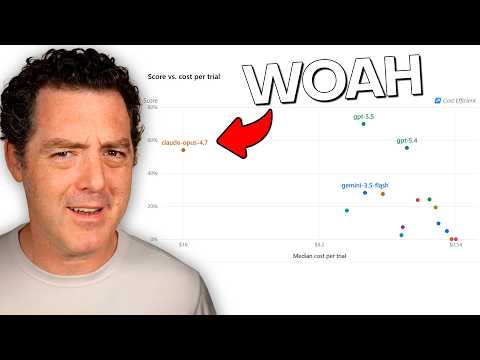
Insights de desempenho: GPT 5.5 lidera o caminho
As avaliações do DeepSWE revelam diferenças claras no desempenho dos modelos de codificação de IA. GPT 5.5 emerge como o de melhor desempenho, alcançando 70% de precisão, mantendo a eficiência de custos e o tempo de execução rápido. Pelo contrário, Opus 4.7embora competitivo em precisão, é menos eficiente e significativamente mais caro. Outros modelos, por exemplo Gêmeos 3.5 Flash e Claude Haiku 4.5demonstrar lacunas significativas de desempenho, destacando áreas para melhoria. Esses resultados fornecem uma compreensão detalhada do desempenho de cada modelo em condições do mundo real.
Insights comportamentais: pontos fortes e fracos
DeepSWE oferece insights valiosos sobre tendências comportamentais em modelos de codificação de IA:
- GPT 5.5: Segue bem as instruções, fornece soluções precisas e eficazes.
- Opus 4.7: Mostra grande consciência ambiental, mas luta com economia e velocidade.
- Claude Haiku 4.5: Luta com prompts multipartes e tarefas paralelas, destacando a necessidade de melhorias.
Essas observações ajudam os desenvolvedores a identificar onde os modelos estão se destacando e onde estão falhando, o que auxilia em melhorias e otimizações futuras.
Equilibrando custo e eficiência
DeepSWE enfatiza a importância de equilibrar eficiência e eficiência de recursos. GPT 5.5 destaca-se como o modelo mais equilibrado que oferece a melhor combinação de precisão, preço e rapidez. No $ 5,80 por teste e uma média de 20 minutos, vence a concorrência como Opus 4.7que é três vezes mais caro e mais lento. Além disso, o GPT 5.5 gera soluções concisas e eficientes com um número médio de tokens de saída menor do que seus equivalentes. Esse foco na eficiência garante que o DeepSWE avalie modelos para atender às necessidades práticas dos desenvolvedores.
Recursos inovadores do DeepSWE
DeepSWE apresenta diversas inovações que o diferenciam dos benchmarks existentes:
- Exploração detalhada: As tarefas incentivam a resolução holística de problemas, em vez de focar em desafios de engenharia superdefinidos.
- Correção de conduta: Os testadores priorizam a precisão funcional em detrimento da similaridade sintática, e os modelos recompensam o desenvolvimento de soluções práticas e funcionais.
Esses recursos garantem que o DeepSWE avalie modelos para atender aos requisitos de desenvolvimento de software do mundo real. Ao focar em resultados práticos, o DeepSWE fornece uma avaliação mais significativa das capacidades do modelo de IA.
Definindo um novo padrão para modelos de codificação de IA
DeepSWE é um avanço significativo na avaliação de modelos de codificação de IA. Ao abordar as limitações dos índices de referência tradicionais e centrar-se nos desafios do mundo real, proporciona um quadro de avaliação abrangente e prático. Com seu sotaque tarefas sem contaminação, vários repositórios, complexidade do mundo reale verificação confiávelDeepSWE estabelece um novo padrão para comparação de modelos de codificação de IA. Isto fornece informações valiosas sobre os seus pontos fortes, fracos e oportunidades de melhoria, abrindo caminho para ferramentas de IA mais eficientes e confiáveis no desenvolvimento de software.
Crédito de mídia: Matthew Berman
Arquivado em: IA, principais notícias
Divulgação: Alguns de nossos artigos contêm links afiliados. Se você comprar algo por meio de um desses links, o Geeky Gadgets poderá ganhar uma comissão de afiliado. Conheça nossa política de divulgação.

")
